Training
While the sentence is being presented, the output nodes are checked for the correct representation of the sentence that is being entered. The value at the output nodes that will be considered correct will be built towards the semantic representation of the full sentence as the words appear. For example, for the sentence the boy ran, when only the word the has been presented at the input, the output nodes should only indicate that the first noun phrase contains a determiner. Then, when the word boy is presented, the output should indicate that the first noun phrase has a determiner, and that the noun is human and singular. Finally, when the word ran is presented, the output should indicate all of the previous output, plus the fact that the verb is one of movement, and that the first noun phrase acts as agent of the first verb phrase.
The language to be used has a total of 508 sentences. There are 64 sentences in group 1, 231 sentences in group 2, and 213 sentences in group 3. Sentences in group 1 have one verb phrase, and one noun phrase. Sentences in group 2 have two noun phrases and one verb phrase. Sentences in group 3 have three noun phrases and either one or two verb phrases.
The basic size of the training set will consist of 20% of the sentences. These 101 sentences will be chosen from the three groups in the following way. Three genes of the network's chromosome will be used to represent a relative worth for each of the sentence groups. The total number of sentences to be used from each group will be 101 X (relative worth of this group)/(sum of the three relative worth). Therefore, we obtain the formula
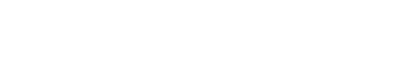
The system will also be able to increase the number of sentences from any of the three sentence groups by requesting so via three additional genes. Since having more training data should naturally lead to better performance, networks that use additional sentences will have their fitness value decreased by a percentage which will be equal to the percentage of additional sentences requested. That is, if a network asks for 17% more sentences, the observed performance value will be decreased by 17%. In this way I will be able to measure how much of a positive effect additional data might have on the network's performance.
There will be a gene in the network's chromosome that will determine how many groups the training set should be divided into. A value between 0 and .25 will mean all sentences will be presented to the network as part of a single training set. A value between .26 and .5 will mean the network will first be presented with sentences from groups 1 and 2. Then, once that training is done, the network will be trained with sentences from group 3. A value between .51 and .75 will mean the network will first be presented with sentences from group 1. Then, once that training is done, the network will be trained with sentences from groups 2 and 3. A value between .76 and 1 will mean the network will be trained first with sentences from group 1, then with sentences from group 2, and finally with sentences from group 3. This will allow a test of Elman's statement that it is important to "start small" when training a network for language tasks.
Finally, a gene will determine it the corresponding network will be trained first with single words from the vocabulary. A gene will be used to indicate what percentage of the nouns and verbs of the language should be used in this first training phase. For each of these words, the input nodes will be activated as if the word were part of a sentence, but the network will only be expected to reproduce the semantics of that one particular word in the first noun phrase block or the first verb phrase block, depending on the type of word. This would be similar to what Nenov and Dyer did in their experiments.
Once the training set has been determined, the network will be trained for 1000 iterations.
 Back to the Table of Content
Back to the Table of Content
 Back to the previous subject
Back to the previous subject To the next subject
To the next subject